Preface
Since my SAS Advanced Exam is approching (May 7, 2021), I wish to use this blog to summarize several key procedures such as SQL and Macro that would be tested in this exam.
If you are preparing the SAS Adv Exam recently, this article could be helpful and you’re also welcome to send me your feedback via any type of contacts at the bottom, thank you :)
TABLE
- PROC SQL Step
- SAS Macro Language
- Advanced Functions and Perl Regular Expression
- Array
- Hash
- PROC FCMP procedure
Proc SQL Step
A proc sql step is composed by three parts:
PROC SQL <options>;
SQL STATEMENTS;
QUIT;
Different from SAS statements, for each SQL procedure inside the PROC SQL step, put ONLY one semicolon in the end. In this section, I assume that you are familiar with the basics in SQL.
Basic clauses, functions and operators
Here is a simple case:
PROC SQL;
create table newtable1 as
select var1, var2, avg(var3) as avgvar3
from lib.table1
where var4 > 1000
group by var1
having avgvar3 > (select avg(var3) from lib.table1)
order by var2;
QUIT;
In this example, we are dealing with one single dataset lib.table1, later we will talk about how to join two tables. (Note: in SAS we could merge multiple datasets at the same time, but in SQL we could only handle two datasets at each time.) And we used most of common clauses in SQL here basically, including: create table –> select –> from –> where –> group by –> having –> order by (ORDER MATTERS!!!).
Speaking of basic functions and operators, there is not a lot of difference compared with SAS (Since we are using SQL in SAS, some features of SAS also works in the proc sql step). The table below is a simple comparison of summary functions:
| SQL | SAS |
|---|---|
| AVG | MEAN |
| COUNT | FREQ, N |
| MAX | MAX |
| MIN | MIN |
| SUM | SUM |
Operations between two or more datasets
In SAS SQL procedure, we often use joins, except, intersect and union steps to do operations between two or more datasets. Here are some common operations:
| Name | Function |
|---|---|
| full join | join all observations in both tables |
| inner join | join the mutual observations in both tables |
| left join | only join the observations existing in the left table |
| right join | only join the observations existing in the right table |
| except | exclude the results in the latter |
| intersect | keep the results in both queries |
| union | combine results in both queries and remove duplicates |
| outer union | concatinate results in both queries |
Note: the joins are used between two tables, but the set operators except, intersect, union, outer union are used between two queries, like this:
proc sql;
select ...
from table1 left join table2
...;
select ...
from table1
except
select ...
from table2;
quit;
There are also another two optional keywords all and corr when using set operators:
ALL: does not suppress duplicate rows
CORR: overlays columns that have the same name in both tables
Subquery
Subquery is another technique frequently used in SAS SQL, which could used to combine data from different tables. As its name indicates, a subquery is also a query but used within an outer query. There are two types: correlated and non-correlated, in this subsection I will only talk about the non-correlated, which excutes independently of the outer query. Like any SQL query, a subquery could return a number, a column or a table, thus it is used to substitute the above objects in a SAS SQL process.
Here is one example using subqueries in where and having statements:
PROC SQL;
create table newtable1 as
select var1, var2, avg(var3) as avgvar3
from lib.table1
where var4 > (select avg(t2_var4) from lib.table2)
group by var1
having avgvar3 > (select avg(var3) from lib.table1)
order by var2;
QUIT;
In a from statement:
proc sql;
select t.var1, t.var2, t.avg(var3) as avgvar3
from (select var1, var2, var3, var4
from lib.table1
where var5 > 1000) as t
where ...
group by ...
having ...
order by ...;
quit;
And we could also use the subquery in the select clause.
In a word, a subquery is very commonly used in proc sql process.
Macro variables
When we talked about the macro variable before, we means something like %let x=10;. In a SAS SQL process, we could assign the returned values to macro variables directly. A simple example is:
proc sql;
select var1
into :mac1
from table1
...;
quit;
We could also define multiple macro variables in the same process:
proc sql;
select var1, var2, var3
into :mac1 - :mac3
from table1
...;
quit;
Note: the syntax above will only assign the value at the first row to macro variables. To assign a list of values to a macro varible, we could use separated by keywords to specify a character to delimit the values as following:
proc sql;
select var1
into :macro1 separated by ', '
from ...;
quit;
I will introduce more advanced knowledge about macro in the next section.
SAS Macro Language
When processing data, we sometimes need to repeat the same/similar work over different datasets in one project. Within a typical SAS program, we usually need to
- write multiple
dataandprocsteps, and then modify the variable values for each dataset - if there are something we want to modify later, we need to modify many places
But a macro function would help us save much time and energy.
TBC
Advanced Functions and Perl Regular Expression
Most of the advanced functions used in the DATA step could be found here.
Lag
Lag function is one commonly used function in SAS, which is to retrieve the previous value for a variable. Because of this, we often use it to compute the mean among the several consecutive values (i.e. moving average) or similar work. Its syntax is as following:
var_prev = LAG<n>(column);
By specifying integer n, we could retrieve our desired previous value.
NOTE: Do not use lag function in a conditional statement such as if-then. A smarter way is to define your lag-related variable at first then put them into your conditional statements
Count, Countc, countw, find, findw
| Functions | Usage |
|---|---|
| COUNT(string, substring<, modifier(s)>) | counts the number of times that a specified substring appears within a character string |
| COUNTC(string, character-list<, modifier(s)>) | counts the number of characters in a string that appear or do not appear in a list of characters |
| COUNTW(c) | counts the number of words in a character string |
| FIND(string, substring<, modifier(s)><, start-position>) | returns the starting position where a substring is found in a string |
| FINDC(string, character-list<, modifier(s)><, start-position>) | returns the starting position where a character from a list of characters is found in a string |
| FINDW(string, character-list<, modifier(s)><, start-position>) | returns the starting position of a word in a string or the number of the word in a string |
Perl Regular Expression
Perl regular expression (abbr PRX) is used to define and search some specific patterns. Personally, its function is kinda similar to the current hot topic NLP (natural language programming), at least they are both used to detect and solve problems in text, although NLP is definitely a more comprehensive and broader field.
In PRX, we need to use different metacharaters to define our text pattern. For example, we could use /\d{3}-\d{3}-\d{4}/ to detect the phone numbers in North America, or we could use /647-\d{3}-d{4}/ and /416-\d{3}-\d{4}/ to retrieve phone numbers in Toronto area. We could do more complex work with PRX. Here is the list of common metacharaters:
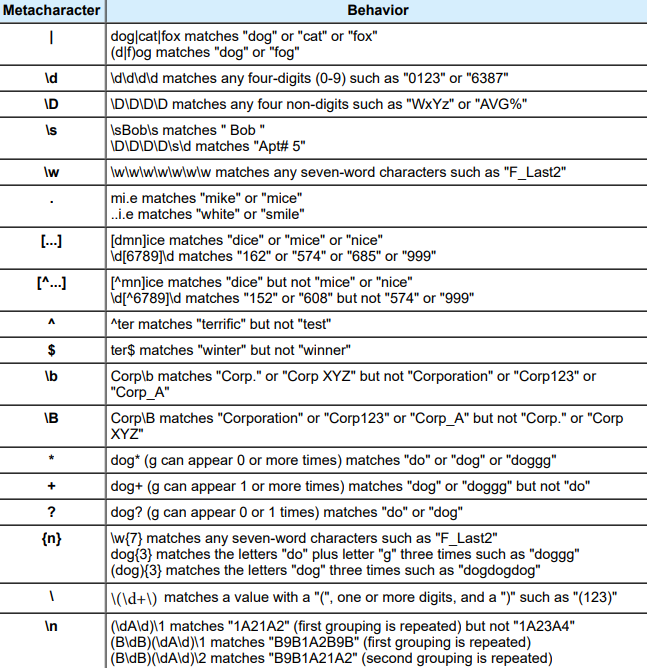
prxmatch is the function we used to check whether objects satisfy the specific pattern that we defined, and returns 0 if not match or the beginning position if match.
LOC = PRXMATCH(perl-regular-expression, source);
The source could be a character constant, a column or an expression. Remember when we are hard-coding the perl regular expression, we need to enclose it with quotation marks. The new column LOC above is the start position of the pattern defined.
prxchange is the function we used to locate and substitute a specific pattern. Its syntax is as following, where times defines the times that we want to search for and substitute the matching pattern, and -1 means all places. Different from prxmatch, we need to name the subtitution we want in the perl regular expression.
PRXCHANGE(perl-regular-expression, times, source)
Here is an example:
new_country = prxchange('/ CH(N.|N|.) / China /i', -1, Country);
With the statement above, I could substitute all CH, CHN, CH., CHN. in the country column with China, and assign them to a new column new_country (i here stands for case-insensitive). You may need to be careful with the spaces when subtituting.
Array
Unlike other languages such as Python or R, array in SAS is a temporary list of columns. By doing this, we could access multiple columns within a loop instead of hard-coding them manually. Its syntax is as following:
ARRAY array-name[number-of-columns] <column-names>;
/* For example */
array xyz[3] col_a col_b col_c;
array xyz[3] col_a -- col_c; * character name
array xyz[3] col1 - col3; * number name
array xyz[3] col: ;
array xyz[*] col: ;
As we can see, we have many ways to define an array in SAS. When we don’t know how mnay columns would be in an array, we could use * to substitute the number. Meanwhile, we could also custom the start point of the array instead of 1 as following:
array col_arr[5:9] col5 - col9;
Also, we could also use array to rotate a table:
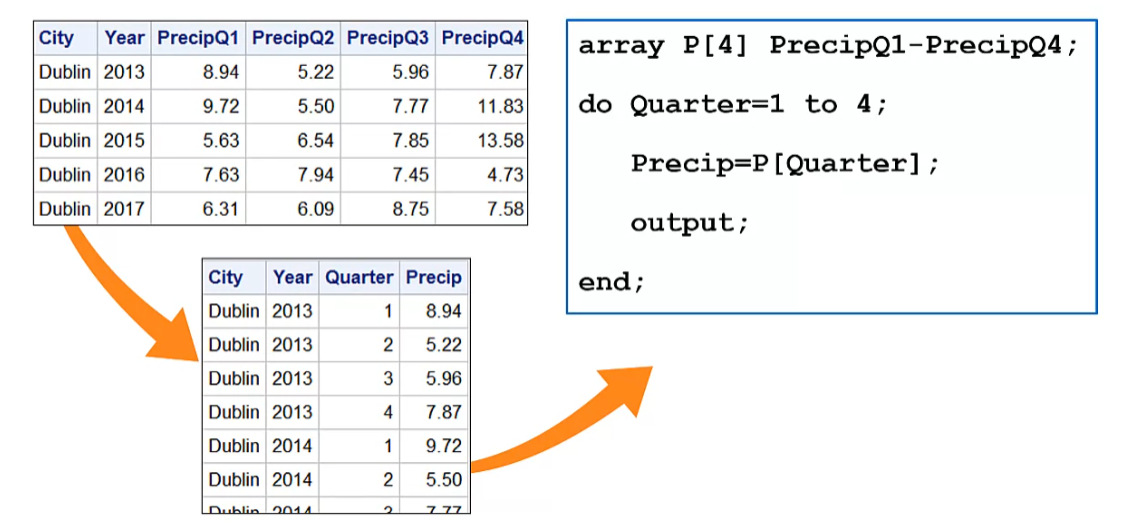
And we could define an array with initial values or a temporary array. Sometimes, we need to compare columns with some fixed values like an average, and we don’t want to keep these fixed values in our table, then we could use a temporary array with initial values like following, otherwise these fixed values will exist as columns in our table unless we drop them specifically.
array col_arr[5] _temporary_ (1,2,3,4,5);
We can also define a two-dim array. The difference is we need to name both numbers of rows and columns. A two-dim array with initial values is like a table in SAS, and in this case, the initial values are assigned by row.
array new_arr[2, 3] (1,2,3,4,5,6);
Except we could define a null array and then assign values to every element within it.
And when creating a character array, we need to add a dollar sign $ following a character length, such as:
array Country[5] $ 8 Coun1-cont5;
Hash
In SQL, there is always a primary key column in each table. The values of that column are unique and could determine each record in a table. In SAS we don’t have such a column, but with hash table we could do similar work. The official document of hash is here.
A hash table is usually used for lookup. By specifying the key’s value, we could retrieve its related information from a hash table. Here is an intact example regarding using hash table:
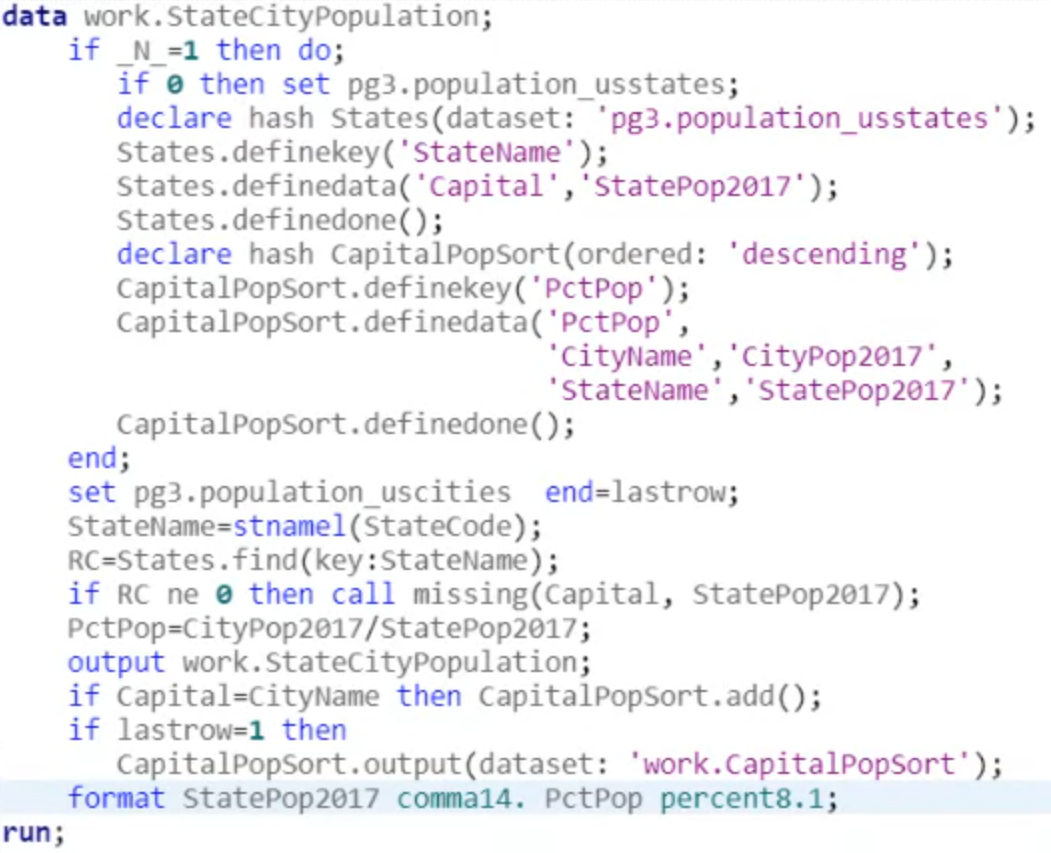
Briefly, we need to define a hash table at first. This table could be loaded from other datasets by dataset argument or a null table, since we could add data into it after defining it. Like we have seen above, here is the syntax:
data ...;
/* build the hash table at the beginning */
if _N_=1 then do;
/* initialize the pdv*/
if 0 then set lib.table;
/* initialize the hash table and load the dataset*/
DECLARE HASH hash-table-name(<dataset: 'lib.table'>);
/* define the keys */
hash-table-name.definekey('key-variable');
/* define the data*/
hash-table-name.definedata('variable1', 'variabl2', 'variable3');
/* end */
hash-table-name.definedone();
end;
...statements...;
run;
And then we need to merge the data of hash table with another table of interest. We could achieve this by using hash.find method. hash.find(key:key-column); returns 0 if the record exists in the hash table, or returns a non-zero value.
data work.newtable;
if _N_=1 then do;
if 0 then set lib.table;
DECLARE HASH h(dataset: 'lib.table');
h.definekey('key-variable-name');
h.definedata('variable1', 'variabl2', 'variable3');
h.definedone();
end;
set table2;
rc = h.find();
if rc = 0 then output newtable;
run;
Notice, we didn’t explicitly tell SAS that we want to add the data in the hash table h to our newtable, this work would be automatically processed when we invoke the h.find() statement.
PROC FCMP PROCEDURE
Like many other language, we could also define our own functions in SAS, this process is called PROC FCMP. Its syntax is as following:
PROC FCMP OUTLIB=libref.table.package;
FUNCTION func-name(arguments) <$> <length>;
...STATEMENTS...;
RETURN(expression);
ENDSUB;
RUN;
Note, package here is a collection of functions that have unique names, and they are also not allowed to have the same name of SAS build-in functions.